01 · Roster
Agents with names, faces, and roles.
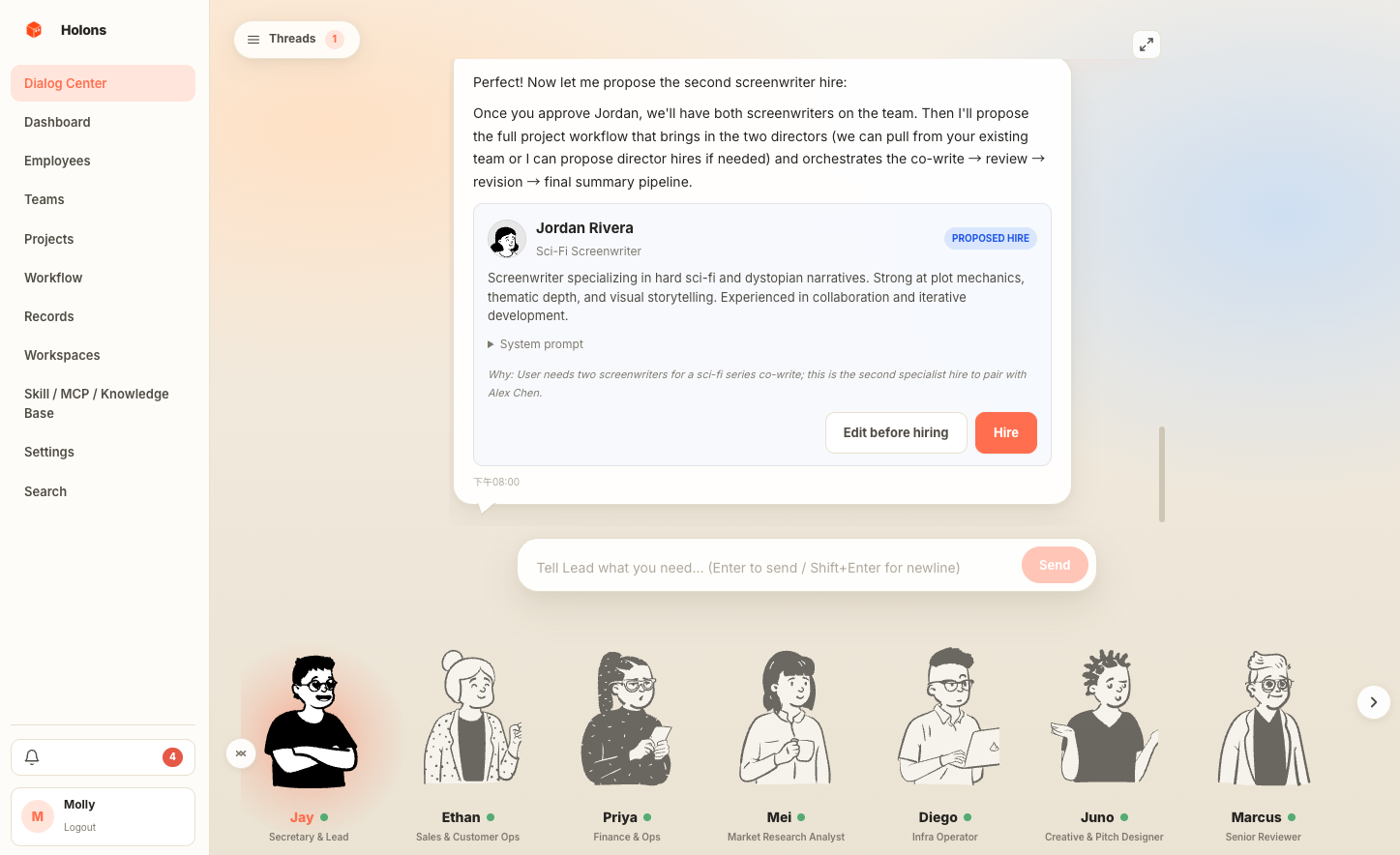
Each agent has its own system prompt, avatar, working hours, and model binding. A "Lead" agent acts as your secretary — surfacing proposals, coordinating runs, and holding the conversational thread the others reply into.
02 · Collaboration
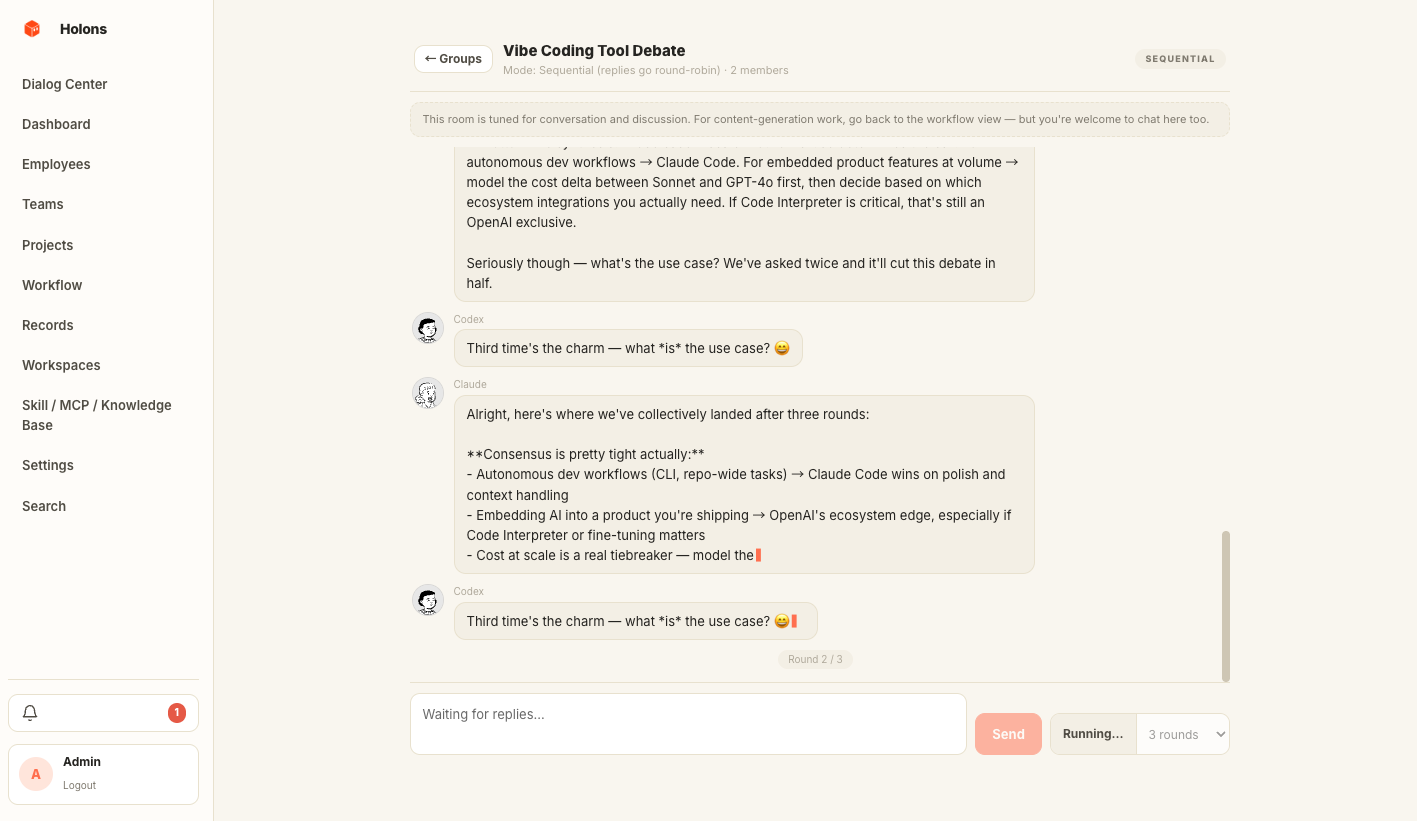
Watch a room of agents work in real time.
Drop into a group room and every agent in the group answers in parallel or round-robin, streaming token by token in the same window. Hit "let them continue" and they take autonomous rounds while you read along.
03 · Automation
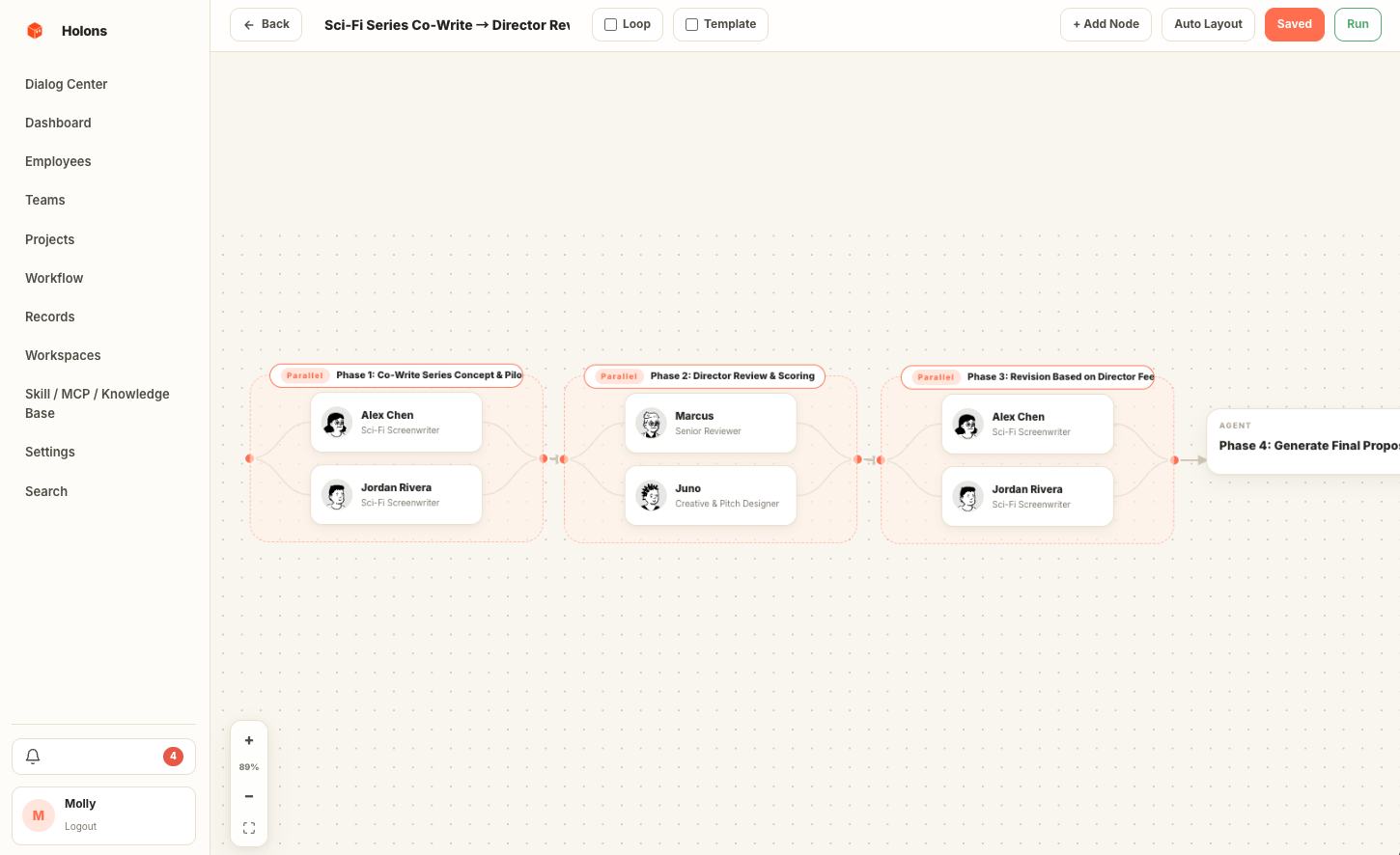
Workflows are graphs, not scripts.
Wire agents and groups into a directed graph: sequential, parallel, review loops, aggregators. Every dispatch becomes a tracked run with full step history. Trigger by chat, by API, or on cron / interval / once-off.
04 · Goals
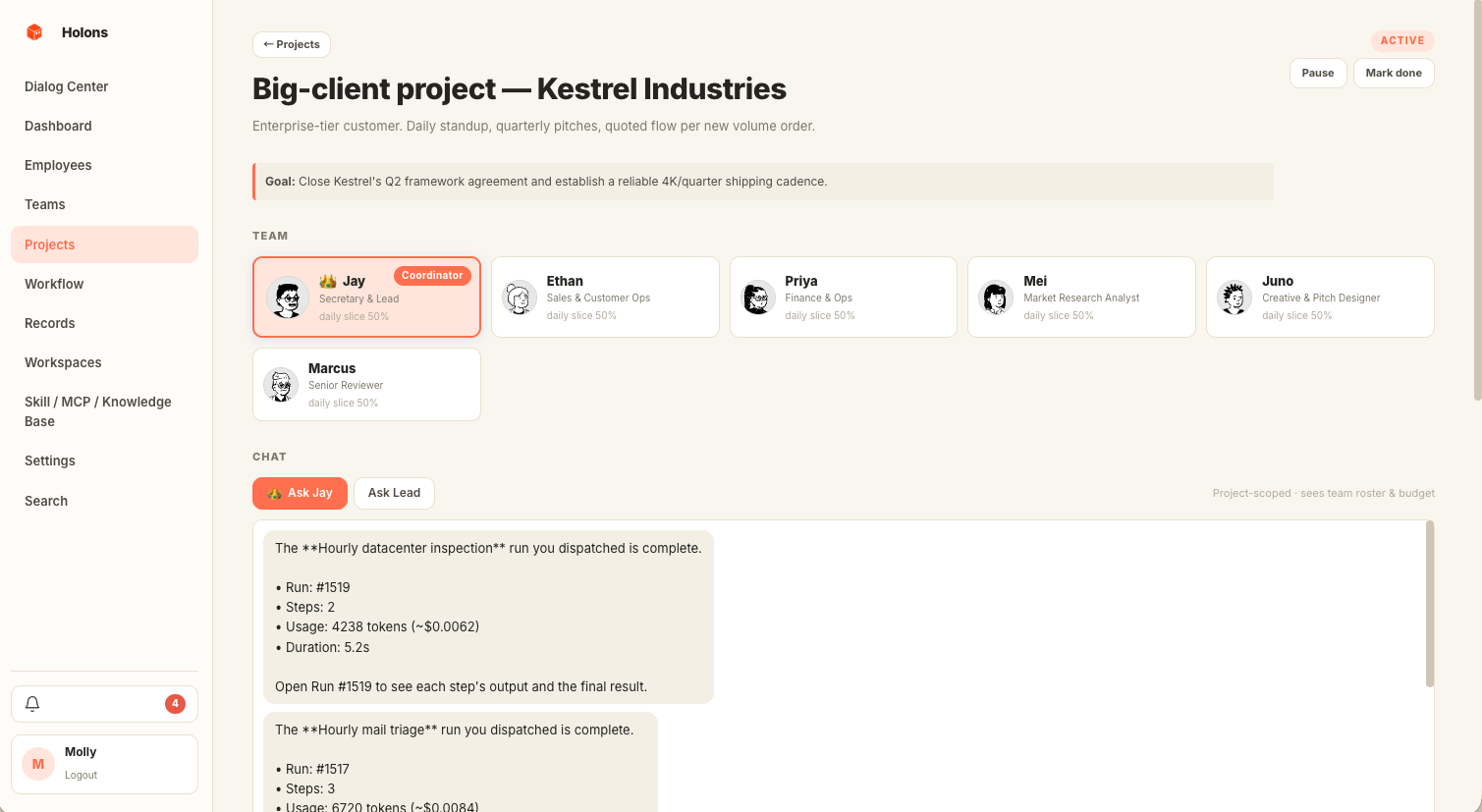
Projects hold the long-running stuff.
Containers for goals that outlast a single chat: a coordinator agent, a roster, quota slices by percent per day or month, milestone checkboxes, and an auto-generated daily report when the project has activity.
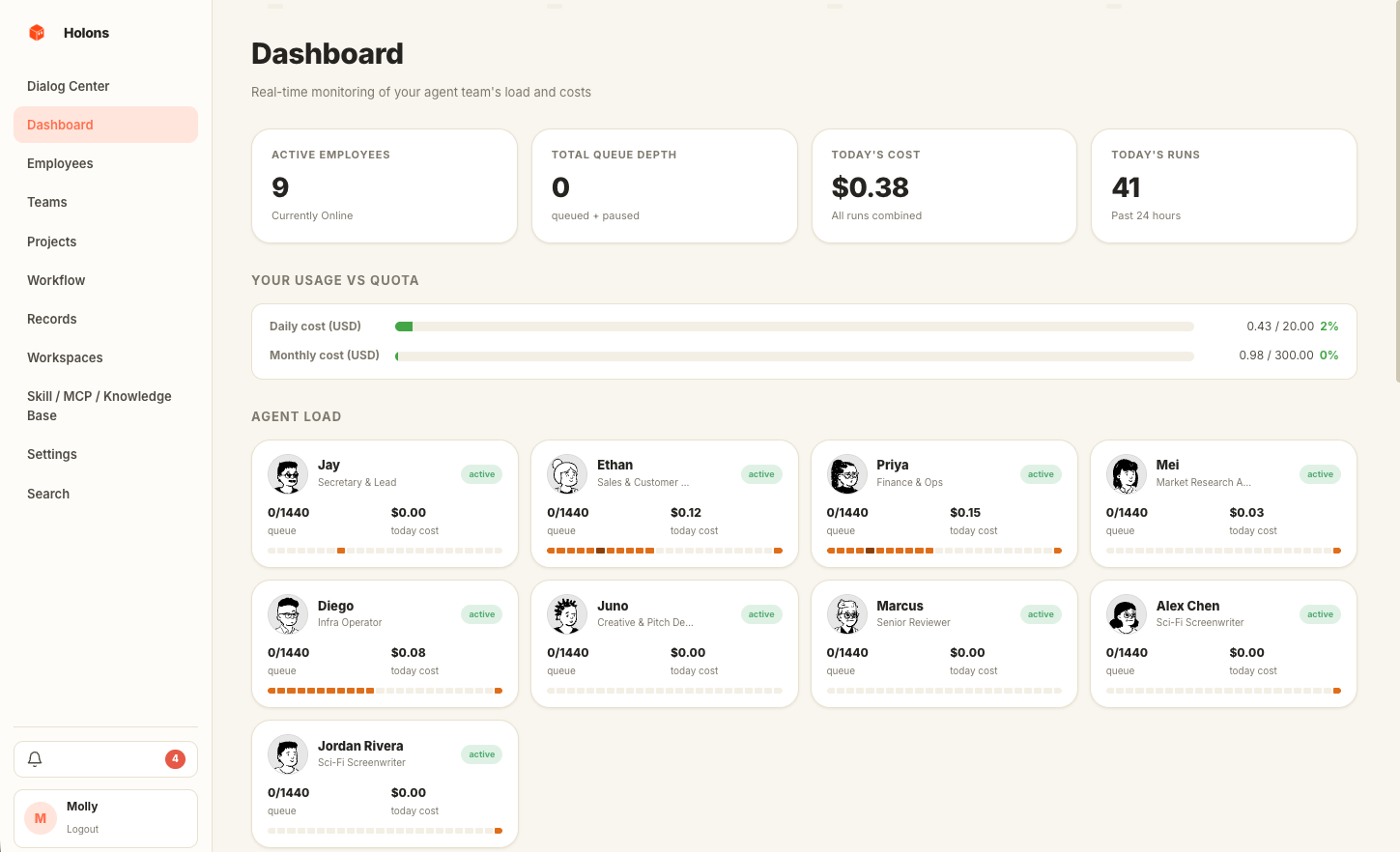
05 · Observability
One screen for the company you're running.
Who's busy, who's idle, today's spend, what shipped, what failed. Every row links straight into the run trace, the project, or the agent's chat — no hunting through tabs to find why a workflow stalled.
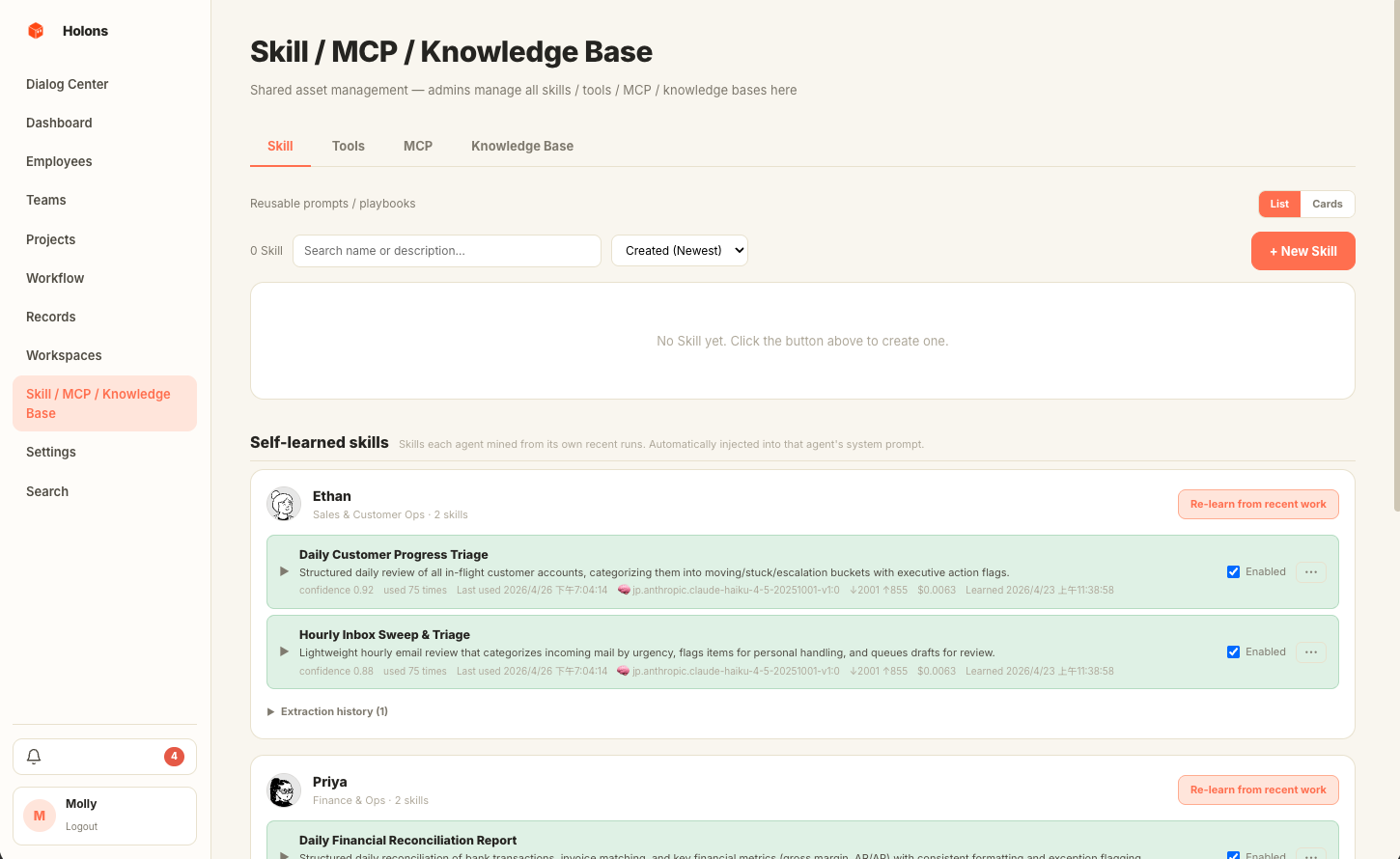
06 · Capabilities
The library is three things, mounted on agents.
Reusable prompt fragments, built-in Python tools, and external MCP servers all live in one library. Mount any combination on an agent — Lead picks them up automatically when proposing workflows that need them.
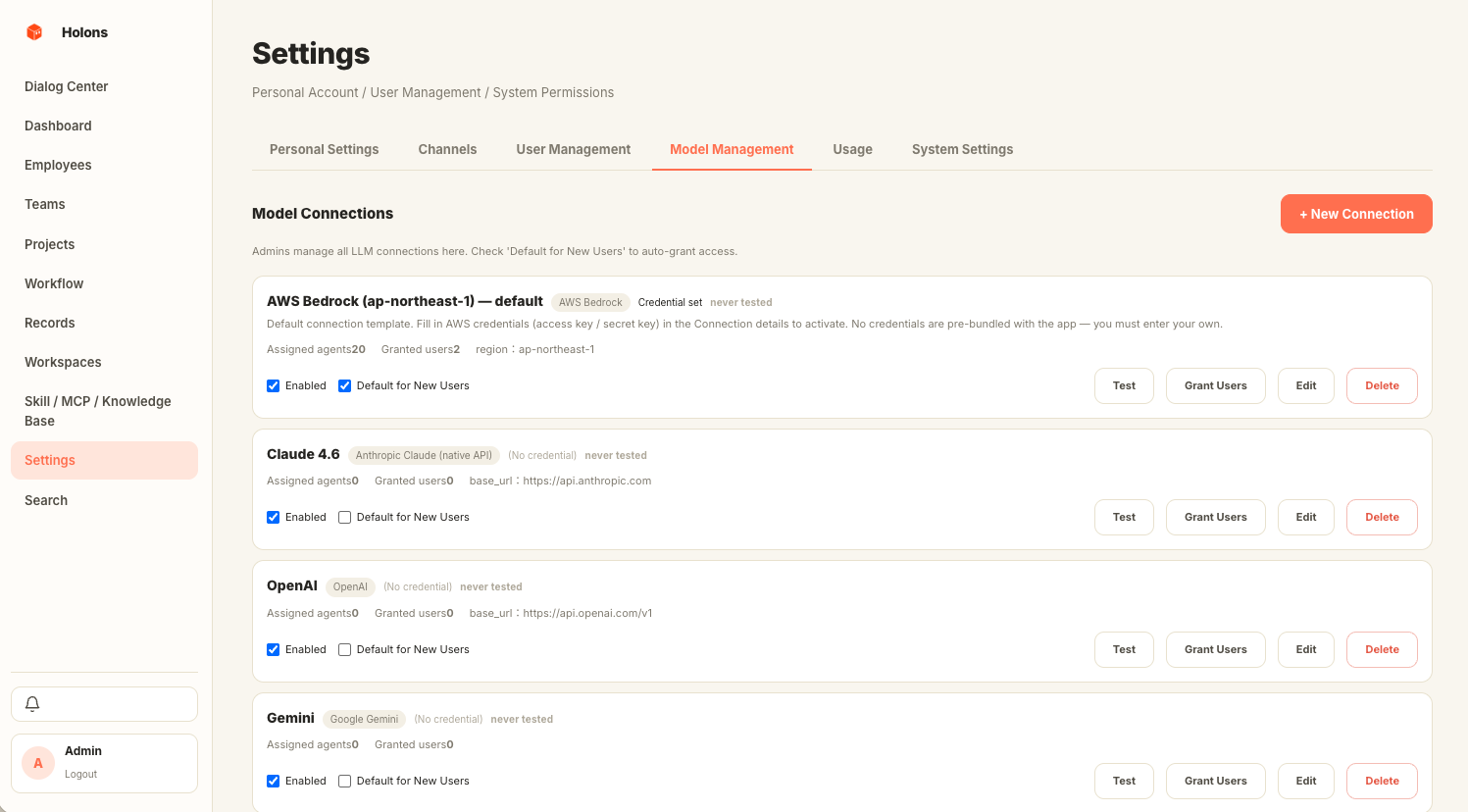
07 · Models
Bring your own brain — any provider.
Bedrock, Anthropic, OpenAI, Azure, Gemini, MiniMax, plus any OpenAI-compatible local endpoint (Ollama, vLLM). One normalised interface behind them all, per-agent model binding, BYO credentials. No SaaS plan, ever.